由于深度学习在图像和语音信号处理上呈现出的核威力,现在NLP也是要慢慢沦陷了,一个个的NLP任务被大牛们刷起来了。今天就来看看深度学习在NLP中命名实体识别的一个简单运用。
背景
这个代码是我在上斯坦福cs224d课程时的作业。大家对深度学习在NLP中的应用有兴趣的话可以去上上这个课程。
在NLP中,一个非常基础的任务就是识别某个单词在上下文中是属于哪一类词的。以下面分类为例:
- Person(PER)
- Organization(ORG)
- Location(LOC)
- Miscellaneous(MISC)
- Null-Class(O)
上面每个类别括号后是该类在数据集中的简写,大家查看数据集就可以发现。事实上大多数词语分到了最后一类Null-Class,也就意味着该类并不代表任何实体。
因此,总的来说,其实我们就是要用深度学习来解决一个分类问题。
模型
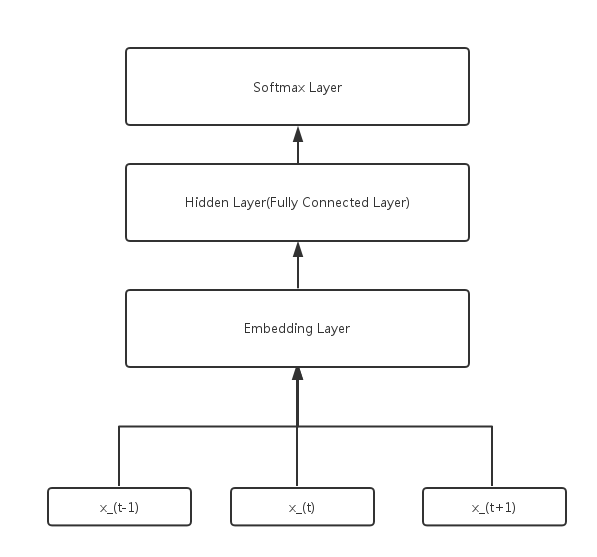
我们搭建一个非常简单的模型,包括一个隐藏层,以及一个word2vec的表示层。另外,在表示一个词的context时,只是简单的用它相邻的两个词表示的:
其中输入,,是one-hot行向量,是embedding matrix, 。
然后添加一个Fully-COnnectted Layer的隐藏层。
最后就是利用softmax进行多分类的概率计算了。
评价指标使用的是交叉熵:
整个网络结构:
代码
我的ipython notebook源码在这里,大家有兴趣的可以看看。