这一章对应NLP项目中的word2vec部分,下面分别讲讲word2vec的理论和实现。
word2vec 理论部分
word2vector简介
也常称之为。近几年由于深度学习的火爆而带动的nlp非常火的词的表示方法。词的表示是nlp处理的一个非常基础的部分,以往的nlp的处理方法基本上都是将词当作最基础的处理单元。但是这样会带来一些问题: 以词为最基础的处理单元:
- 词以其在词库中的索引来表示
- 词与词之间的相似性等无法得到表示
- 简单,鲁棒,简单的模型在大量数据下的表现比复杂模型在少量数据下更佳
- 很多场景下的任务性能受限于数据量,同时,简单的增加数据量可能不会带来很大的改善
因此,这个更复杂的模型应运而生。它也确实比之前简单的模型表现的更好。
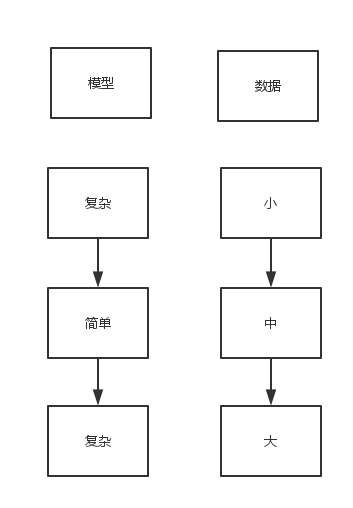
当然,这和硬件的发展是分不开的。
语言模型
以下面这句话为例: ‘The cat jumped over the puddle’ 一个好的语言模型会对一句符合人类理解的、语法、语义的话语给予很高的概率。然而,对‘stock boil fish is toy’应该给予很低的概率。对于一句有n个单词的语句,我们给予它的概率记为: 假设每个单词出现是独立的。那就可以得到以下: 这个模型是以每个单词的出现是相互独立为基础的,这个模型我们称之为unigram-model,但是显然,这个假设很牵强,很多时候,一句话前后的单词是有联系的。因此,为了改善模型,我们假设每个单词出现的概率和前一个单词有关系,称之为bigram-model。那么就得到如下: 显然这个模型的假设依然有些牵强,可是却带来了很好的效果。 下面我们来看看在中的模型
模型和模型。
模型
工作原理
‘The cat jumped over the puddle’,对于这句话,我们将{‘the’,’cat’,’over’,’the’,’puddle’}当作context,用来预测产生词语’jumped’。整个预测过程分为以下几步:
Input:, context words
Parameters:
m:context size
:input word matrix
:output word matrix
Output:
, central word
- 生成输入的句子,采用的one-hot编码,, 大小为m。
- 得到embedded vectors
- 取平均:
- 得到一个分数vector,
- 将分数转化为概率
因此,在知道U和V的时候,我们知道如何预测central word。那么接下来问题就变成了如何获得输入单词矩阵V和输出单词矩阵U了。换言之,
如何训练模型得到V和U
在这里,我们采用信息论中的交叉熵(cross-entropy)作为我们的目标函数, 对于one-hot编码,y中只有正确的那个位置为1,其余的都为0。因此上式变成了: 也就是上面第五步中得到的概率。下面换个标记代表我们的最优函数目标。
然后使用梯度下降等方法更新U()和V(v_j)
模型
工作原理
skip-gram模型则和CBOW模型相反,是给定central word,预测context words。‘The cat jumped over the puddle’,对于这句话,我们将给定词语’jumped’,想预测产生{‘the’,’cat’,’over’,’the’,’puddle’}当作context。
Input:, central word
Parameters:
m:context size
:input word matrix
:output word matrix
Output:
,context words
- 生成输入的词语,采用的one-hot编码。
- 得到embedded vector,
- 这里不用像CBOW一样取平均,只用
- 产生2m个分数vector, ,
- 将分数转化为概率,
因此,在知道U和V的时候,我们知道如何预测context word。那么接下来问题就变成了如何获得输入单词矩阵V和输出单词矩阵U了。换言之,
如何训练模型得到V和U
在这里,我们采用信息论中的交叉熵(cross-entropy)作为我们的目标函数, 对于one-hot编码,y中只有正确的那个位置为1,其余的都为0。因此上式变成了: 也就是上面第五步中得到的概率。下面换个标记代表我们的最优函数目标。但这里有一个假设,就是假设所有的context输出是独立的。 假设一个训练集为 目标函数:最大化以下函数:
另外,skip-gram模型中用简单的softmax函数定义 :
因此,综合以上,也就是最小化一下函数:
Negative Sampling
可以发现上面的目标函数,需要在整个vocabulary上求和。要知道|V|是百万量级的,运算量太大了。因此,我们可以在性能允许的范围内近似计算。近似的思想就是不在整个vocabulary上求和,取而代之的是只在其中一部分上求和。因此我们要产生能近似代表整个vocabulary的这一部分。很简单,我只需要采样一些负样本(negative samples)就行了。我们从噪声分布()采样。这个噪声分布是vocabulary中词的频率产生的。
negative sampling是基于skip-gram model的。那么如何将其和上面的模型结合起来呢?
考虑一对(w,c)代表word和context。那么它是否来自于训练数据集呢?
用以下符号:
:(w,c)来自语料库的概率;
:(w,c)不是来自语料库的概率;
用sigmoid函数建模的时候,
这里的指代上面模型中的U和V。
接下来,我们构建一个新的目标函数用来最大化假如(w,c)确实来自语料库时的概率和最大化假如(w,c)确实不来自语料库时的概率。
上式中的代表negative corpus。我们可以从vocabulary中随机采样产生这个negative corpus。 假如我们采样数为K个的话,那么上式变为: 对于小的训练集,通常取K=5-20,而对于很大的训练集,K=2-5之间就近似的很有效。
Negative sampling需要噪声分布。经实验发现,时比和均匀分布时在很多任务中表现的更好,其中是unigram 分布,Z是归一化常数。 为何取3/4呢?数学上的原因可能难以解释。不过我们还是可以从下面得到一些启示。 假设语料库由{‘is’:0.9, ‘constituition’:0.09,’bombastic’:0.01}组成。 可以发现,’bombastic’采样的概率是以前的3倍多了,而’is’采样的概率却只增加了一点。
Word2vec 实践部分
实践部分是照着tensorflow官方流程走了一遍,如果自己要想有更深的理解,敲一遍是必不可少的。当然,为了节约时间,用python notebook可以加速原型开发。另外,官网代码仅作参考,比如代码结构之类,这样也能体现自己的整个思维。 下面仅就一些核心函数讲解: 以skip-gram模型为例。 符号和前面所讲对应。 下面两个函数基本上就描述了整个建模过程:
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
loss = tf.reduce_mean(tf.nn.nce_loss(nce_weights, nce_bias,
embed, train_labels,
num_sampled=num_sampled,
num_classes=vocabulary_size))
train_inputs: x
embeddings: V
embed:
nce_weight+nce_bias: U
另外,nce_loss采用的就是类似于计算negative sampling之后的目标函数。 这个版本是最基础最快的版本,大家可以在上面修改调参获得更好的性能。
源码链接
以下是python notebook版本。
py版本可以在tensorflow官网找到。
参考文献
[1]Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[C]. Neural Information Processing Systems, 2013.
[2]http://cs224d.stanford.edu/
[3]https://www.tensorflow.org/versions/r0.10/tutorials/word2vec/index.html#vector-representations-of-words